PostgreSQL
A relational database management system (RDBMS).
Learn
- Official tutorial
- https://www.postgresqltutorial.com
- https://pgexercises.com
- #todo https://theartofpostgresql.com
- https://challahscript.com/what_i_wish_someone_told_me_about_postgres
- https://mccue.dev/pages/3-11-25-life-altering-postgresql-patterns
Notes:
- The server program is called
postgres. - The default database name is
postgres. - Use
defaultto automatically insert default values. - Use
to_charto format output. - Terminology:
- DDL: data definition language (
CREATE/ALTER/DROP). - DML: data manipulation language (
INSERT/UPDATE/DELETE).
- DDL: data definition language (
Best practices
- Use
bigintfor ids by default,uuidfor "random" ids. - Use identity columns (
GENERATED ALWAYS AS IDENTITY) instead ofserialfor ids. - Use
textinstead ofchar/varcharfor strings. - Use
timestamptzinstead oftimestampfor dates. - Use
JOIN/ONinstead ofFROM/WHEREfor joins. - Use CTEs (
WITH) instead of subqueries. - Use
COPYto insert large amounts of data from files. - Create indexes for production tables
CONCURRENTLY.
See also Don't Do This.
Constraints
https://www.postgresql.org/docs/current/ddl-constraints.html
CHECK: ensures the expression is trueNOT NULL: ensures the value is not nullUNIQUE: ensures the value is unique across all the rowsPRIMARY KEY: marks the column as the primary keyREFERENCES (FOREIGN KEY): ensures the value exists in another table
Views
A view is a named query that behaves like a table. It is useful to write a long query once and then reuse it as a view.
Syntax: CREATE VIEW <name> AS <query>;
#todo Materialized view: a view that is stored on disk.
Foreign keys
A foreign key is a type of constraint that ensures referential integrity between two related tables. It prevents inserting a row into one table if the corresponding row does not exist in another table.
Example: inserting into weather(city) requires the city to exist in cities.
When a referenced row is deleted (ON DELETE):
RESTRICT: raise an errorCASCADE: delete the referencing rowsSET NULL/DEFAULT: set the referencing rows to nulls or their default values
Transactions
A transaction combines multiple queries into an atomic (all-or-nothing) operation.
Syntax: BEGIN; ... COMMIT/ROLLBACK;
ACID properties:
- Atomicity: either all changes made by a transaction are written, or none.
- Consistency: a transaction brings the database from one valid state to another.
- Isolation: changes made by an open transaction are not visible to other transactions until it is committed (ensured by MVCC).
- Durability: changes made by a committed transaction will be written even if the system goes down (ensured by WAL).
Anomalies:
- Dirty read: a transaction sees changes made by another uncommitted transaction.
- Nonrepeatable read: a transaction reads the same data twice and finds that some rows have been modified by another committed transaction.
- Phantom read: a transaction reads the same data twice and finds that some rows have been added/deleted by another committed transaction.
- Serialization anomaly: the order of changes made by multiple concurrent transactions is inconsistent.
Isolation levels:
- Read uncommitted: (not implemented due to MVCC) all 4 anomalies are possible.
- Read committed: (default) prevents Dirty read.
- Repeatable read: prevents Nonrepeatable and Phantom read.
- Serializable: prevents Serialization anomaly, i.e. running concurrent transactions must have the same effect as running them sequentially.
Use BEGIN TRANSACTION ISOLATION LEVEL level to start a transaction with a specific isolation level.
⚠️ Warning
Applications that use Repeatable read and Serializable isolation levels must be prepared to retry transactions that fail due to serialization errors.
See also Postgres Concurrency Issues.
MVCC
Multiversion Concurrency Control is used to implement concurrent transactions. The idea is that each transaction works with its own snapshot of the database. The main advantage of MVCC over locking is that reading does not block writing and vice versa.
Updating a table row creates a new version of it instead of overwriting the original data.
To remove obsolete versions, a garbage collection must be performed using the VACUUM command.
Postgres includes the autovacuum daemon, which runs VACUUM (and ANALYZE) automatically.
It is enabled by default.
WAL
Write-Ahead Logging is used to ensure data integrity. The idea is to persistently log all database changes before they are actually written. This way, even if the system goes down, the changes can be recovered later from the log.
Indexes
https://use-the-index-luke.com
Normally, all table rows are scanned to find matching elements. To perform more efficient scans, an additional data structure called an index is used. Thus, indexes speed up read queries at the cost of using more disk space and slowing down write queries (due to necessary index maintenance). Once an index is created, it is automatically updated when the table is modified.
Syntax: CREATE INDEX index ON table (columns);
It is possible to define an index on multiple columns.
The order of the columns is important: a multicolumn index can only be used to search by the leftmost columns.
Example: foo_bar_idx(foo, bar) can be used to search by foo and bar, by foo, but not by bar.
💡 Hint
For best performance, index for equality first, then for ranges.
💡 Hint
AvoidLIKEexpressions that start with a wildcard (e.g.%foo) as they cannot be indexed.
Since an index only contains the values of the columns it was built for, it is still necessary to fetch the values of other columns from the table data.
A unique index is automatically created when a primary key or a unique constraint is used.
Index usage can be examined using EXPLAIN.
The default index type is B-tree, where the leaves contain pointers to the table rows and form a sorted linked list. There are 3 steps querying data using an index:
- Tree traversal (to find the queried values)
- Linked list iteration (to find all matching entries)
- Table data fetch (to get the actual table rows)
If an index covers all columns used in a query,
an index-only scan can be performed.
Non-key columns can be added to an index using INCLUDE (columns).
If only a subset of column values is used in a hot-path query,
a partial index may be a better fit.
Example: index only unprocessed orders (orders.processed = false), because processed orders are only queried by id.
⚠️ Warning
Postgres does not automatically create indexes for foreign keys.
⚠️ Warning
Write operations (INSERT,UPDATE,DELETE) on a table are blocked until an index is built! This may be unacceptable for large tables in production. To prevent this, create indexes for themCONCURRENTLY.
✏️ Note
Force using indexes for debugging purposesSET enable_seqscan = OFF;
Query plan
The EXPLAIN [ANALYZE] command prints the execution plan for a query (ANALYZE causes it to actually be executed).
The query planner uses the statistics of a database to generate optimal execution plans.
The ANALYZE command is used to update these statistics.
💡 Hint
UseBEGIN; EXPLAIN ANALYZE ...; ROLLBACK;to get the actual time forINSERT/UPDATE/DELETEqueries without modifying data.
Scan operations:
- Seq Scan: full table scan
- Index Scan: index traversal with table data fetch
- Index Only Scan: index traversal without table data fetch
- Bitmap Index Scan + Bitmap Heap Scan:
- index traversal to get all pointers to queried rows
- creating a bitmap of table heap pages containing queried rows
- table data fetch scanning only those pages
Join operations:
- Nested Loop: joining two tables using a nested loop
- Hash Join: joining two tables using an in-memory hash table
- Merge Join: joining two tables sorted by the join key
Locks
Table-level locks:
LOCK: locks a table manually.
Row-level locks:
SELECT FOR UPDATE: locks the selected rows for writing until the end of the transaction.SELECT FOR SHARE: same asSELECT FOR UPDATE, but multipleSELECT FOR SHAREtransactions do not block each other.
#todo Advisory locks:
- pg_advisory_lock
⚠️ Warning
The effect on foreign keysSELECT FOR UPDATEalso locks referenced values (not full rows) from other tables.
A read-modify-write operation can be implemented using different types of locking:
- Pessimistic: an application reads data with
SELECT FOR UPDATE, modifies it, and writes it back. - Optimistic: an application reads data without locking, modifies it, and writes it back, repeating the transaction if the data has been updated since.
- Serializable: an application reads data in a Serializable transaction, modifies it, and writes it back, repeating the transaction if it fails with a serialization error.
See also:
- https://pglocks.org
- https://shiroyasha.io/selecting-for-share-and-update-in-postgresql.html
- https://www.2ndquadrant.com/en/blog/postgresql-anti-patterns-read-modify-write-cycles
Prepared statements
A prepared statement is a pre-compiled SQL code separated from data. It can be used repeatedly with different parameters without recompilation.
There are two types of prepared statements:
- Unnamed: created automatically for each query.
- Named: created manually with
PREPARE; exist during the session.
⚠️ Warning
Using prepared statements is a critical part of protecting against SQL injections. Never build SQL queries from raw user input!
WITH queries
Also known as Common Table Expressions (CTEs). Used to split complex queries into smaller parts, which can then be referenced by the main part. Generally preferred over subqueries due to better readability.
Syntax: WITH foo AS (...) SELECT * FROM bar;
CTEs can also be used for recursive queries.
Window functions
Like aggregate functions, window functions perform calculations across a set of rows (called a partition). Unlike aggregate functions, these rows are not grouped in the output. Window functions are computed across the rows in the same partition as the current row.
Use case: for each row calculate something that depends on other rows.
Syntax: SELECT fn(foo) OVER (PARTITION BY bar ORDER BY baz)
If PARTITION BY is omitted, a single partition containing all rows is used.
Window functions are computed after any grouping, aggregating, and filtering is done.
Grouping sets
Grouping sets are used to group by different combinations of columns in the same query.
This is an alternative to separate GROUP BY queries combined using UNION ALL.
Syntax: GROUP BY GROUPING SETS ((foo), (bar))
Shorthands:
CUBE (foo, bar)->GROUPING SETS ((foo, bar), (foo), ())ROLLUP (foo, bar)->GROUPING SETS ((foo, bar), (foo), (bar), ())(all possible subsets)
Cursors
A cursor is similar to an iterator in programming languages. It can be thought of as a pointer to a row in a set of rows. Cursors are used to avoid loading the entire query output into memory at once.
Syntax: DECLARE cursor CURSOR FOR SELECT * FROM table;
The FETCH command is used to retrieve rows from a cursor.
Triggers
A trigger is a function that is automatically executed when a certain event occurs on a table.
Triggers provide access to values before and after a change: NEW.column and OLD.column.
LISTEN/NOTIFY
A builtin pub/sub mechanism. Can be used to avoid database polling. A message is received by all connected listeners.
⚠️ Warning
If there are no listeners at the moment, a sent message will be lost.
Example:
- Alice:
LISTEN channel; - Bob:
NOTIFY channel, 'hello';
Pagination
- Offset-based: easier to implement (
OFFSET), slow for large amounts of data. - Cursor-based: harder to implement (
WHERE id < $last_seen_id), cannot jump to a specific page.
See https://use-the-index-luke.com/no-offset for details.
psql
An official Postgres CLI client.
Tools:
createdb <dbname>: create a databasedropdb <dbname>: delete a databasepsql <dbname>: access a database
Commands:
\?: help\h: help for SQL commands\l: list databases\d: list tables/views\d <name>: show table/view info\i: source the given SQL file\e: edit the last command with $EDITOR\q: quit
Maintenance
Backup
pg_dump: generate a file with SQL commands that recreate the database in the same state.
Replication
Replication is the process of maintaining multiple copies of a database, such as primary (used for writes) and replica (used for reads). It is used to scale a database for reading.
- #todo sync vs async replication
- #todo replica vs backup
Sharding
Sharding is the process of partitioning a database between different servers, e.g. table1 on server1, table2 on server2, etc. It is used to scale a database for writing.
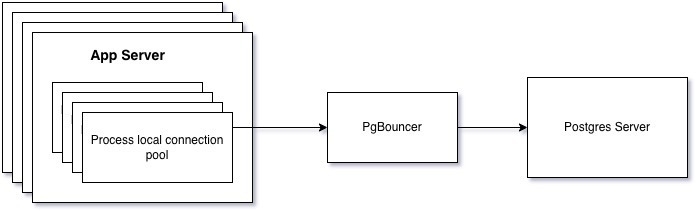
Connection pool
Since opening new database connections is not cheap, a connection pool can be used to reuse existing connections.
- Go's database/sql.DB
- PgBouncer (commonly used as a proxy server)
Performance tuning
See also
- PGTune
- EXPLAIN Visualization
- Postgres as a queue
- Open a transaction
- Run
SELECT FOR UPDATE SKIP LOCKEDto pick a job - Hold the transaction open until the job is done